

When you as a software developer start examining a new project’s specifications that just arrived at your team, you start planning the architecture. Every application uses data handling and storing, so you will need a database.
Nowadays, there are tons out on the market, so you can become confused with which one to choose. Well, it highly depends on what your soon to be app is about.
In this blog post, we will discuss the opportunities of file storing with relational and NoSQL databases through the comparison of MongoDB and SQL Server.
First, we must get clear about the data that appears in databases.
- Structured: These kinds of data are easily stored in the strict template of a relational scheme (of course in NoSQL databases too) and efficiently ordered, searched and filtered on different properties of an object.
- Semi-structured: Loosely structured data, the entities belonging to the same class may have different attributes, even though they are grouped together. Usually, these are stored in ‘xml’ data type in the relational case
- Not structured: The data cannot be organised into a scheme, for example, binary data. These data types are called Binary Large Objects (BLOB).
In this post, we’re focusing on the third (not structured) data types.

MAIN DATABASE MANAGEMENT SYSTEMS
There are two main database management systems out there, RDBMS and NoSQL(key-value stores, column family stores, document databases, graph databases. For more info check out this website).
Both are suitable for storing structured and semi-structured data but not structured (BLOB) data could cause a headache when using it with relational databases.
The usual approach is to store the file-data in other parts of the file system, only the path or reference can be found in the DB. However, with this comes a problem: keeping the consistency between the file system and the records in the tables.
I will present you one DBMS from each type, MongoDB and SQL Server from Microsoft.
SQL Server provides 3 basic modes to store binary files.
- File system
- Varbinary(max)
- Filestream
This table shows the main differences:
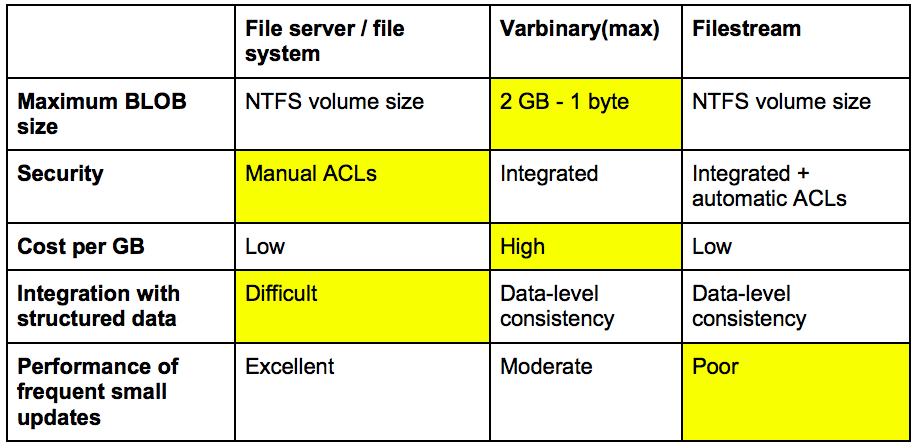
As you can see, the Filestream uses the positive things from the other two, making it an ideal choice instead of the others. Microsoft says that under 1MB you should use the varbinary(max) for better performance, above that the Filestream is more appropriate.
Another piece of research concluded that BLOBs smaller than 256kB should be stored in the DB, while bigger than 1 MB rather on the file system; the choice of the interval between depends on the number of reads and writes. See some best practices here.
In MongoDB, data is organised to documents (records in RDBMS) inside collections (tables in RDBMS), without a strict structural scheme. In one collection, there can be documents with different properties, though they must be in some logical relation to others in the same collection.
For example, it is not a good idea for a cat to be stored between a fish; it would be uncomfortable for both sides.
The problem is that a document cannot be larger than 16MB, but they’ve already come up with a solution, called GridFS.
This special technique enables the storing of large BLOBs, i.e. picture, music, video or anything else in the database files. The files are divided into 255kB blocks; each block gets one document, that’s called chunks.
To implement this, GridFS uses two collections; one is fs.files the other is fs.chunks, metadata goes into the files while binary is in the chunks array.
These little parts have ids, reference to the file and an index to rebuild them in the correct order and the binary data itself. If the last one does not need the predefined place, it leaves the remaining segments free for other documents. Besides this, you can load only the desired sections of a huge file into the memory to get the precious data.
{
"_id":<ObjectId>, // Unique identifier
"files_id" : <ObjectId>, // The files identifier, to which this part belongs
"n": <num>, // Ordinal number in file chunks of the file
"data" : <binary> // BSON data
}GridFS uses an index on every chunk and file to increase performance; we can define our own custom index too. It’s recommended to use this technique with files larger than 16MB.
MONGODB AND SQL SERVER COMPARISON
I created a demo app with different entities and relations, and two database layers, one with a JPA implementation for MongoDB and other NoSQL databases (Kundera) and one for SQL Server and relational databases (Hibernate).
The following table highlights the time results for both solutions with different files.
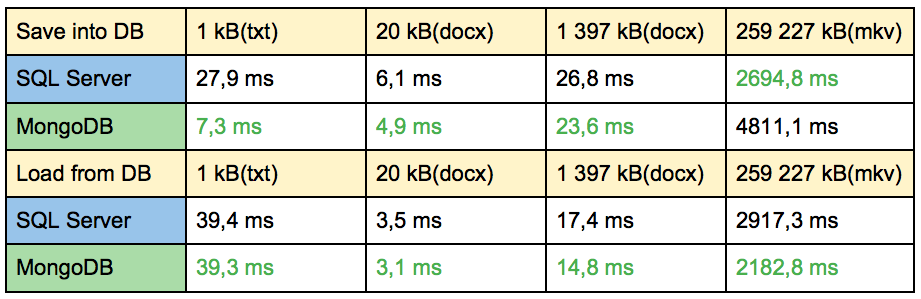
Each number is the average of 10 measures.
Does that mean you have to choose from one of the above when exposing files? The answer is absolutely not. The good old File System is still the fastest kid on the ground, I highly recommend it when you have gigantic files. You should also check out static content distributers for providing media more efficiently.
READY TO UPGRADE?


_ We’re a full-stack web development agency, building web applications from design to delivery with Angular, React, and Node.js



